

You have a business continuity plan. It was probably created for an auditor or an insurer. It sits on a shelf, a digital artifact of compliance, costing you silent risk every day it goes untested. When a real crisis hits—a key vendor goes down, ransomware locks your files, or a critical platform fails—that plan is worthless.
What follows is chaos. Your leaders scramble to find owners who were never assigned. Your teams argue over which service to restore first. Communication breaks down. This isn't a failure of smart people. It's the predictable result of an ambiguous operating system where ownership is fuzzy and critical decisions were never made ahead of time.
The Real Problem: Your Plan Is an Artifact, Not a System
You have smart people. You have expensive tools. You might even have a thick binder labeled “Business Continuity Plan.” But when a real disruption hits, the entire structure crumbles. This is an operating system failure, plain and simple.
The problem persists because the plan exists as a static document, disconnected from how your company actually operates. Policies on paper are useless without clear ownership, defined decision rights, and a regular cadence for practice. Smart people fail in ambiguous systems.
Let’s look at a real-world scenario. A mid-sized financial services firm gets hit with a ransomware attack. Someone dusts off the continuity plan, last updated 18 months ago.
- The Owner is Gone: The primary contact in the plan left the company six months ago. The secondary contact is on vacation.
- The Escalation Path is Broken: The plan says to contact the "IT Steering Committee," a group that hasn’t met in a year and has no clear leader. No one is empowered to make the million-dollar decision: pay the ransom or start a full restoration?
- Dependencies are Invisible: The plan overlooks a critical third-party payment processor. That vendor's system is also compromised, but no one has a contact number.
This paralysis costs the firm dearly. Hours bleed into days. Customer accounts are frozen and trust plummets. The plan didn't fail because it was poorly written. It failed because it was never integrated into the operational fabric of the business. The reality is that businesses struggle to recover after a crisis when their plan is just a story they tell themselves.
The Decision: Build an Inspectable System of Readiness
You have a choice. You can continue to rely on heroics during a crisis, hoping that dusty plan is "good enough." Or you can make the decision to build a system for resilience that you can actually inspect. This isn't about buying another platform. It's about installing a new operating system for how you navigate disruptions.
This decision starts with delegating clear ownership. Your first job is to name one person—not a committee—responsible for the health and readiness of the entire continuity program. This owner is accountable for driving the work and producing proof. Once empowered, this owner will:
- Map Critical Services: Identify the 5-10 business functions that, if they go down, would cause catastrophic damage to revenue or reputation.
- Define Dependencies: Make the invisible visible by connecting those critical services to the specific people, systems, and vendors they depend on.
- Establish a Rhythm: Implement a steady, predictable cadence of testing, reviewing, and improving the plan.
The second part of the decision is to define your risk appetite in plain English. For your board and executive team, this means approving your tolerance for downtime and data loss. This translates an abstract issue into a matter of governance and delegated authority.
For each essential service, you must answer two questions:
- Recovery Time Objective (RTO): How quickly must this service be back online before we start bleeding money or losing trust? Is it one hour? Four hours? 24 hours? This is the maximum acceptable downtime.
- Recovery Point Objective (RPO): How much data can we afford to lose? Are we okay with losing a day of work, or can we only tolerate losing five minutes of transactions? This is the maximum acceptable data loss.
These are business decisions, not technical guesses. When leadership signs off, you give your teams clear guardrails to build and test against. You can explore disaster recovery plan best practices that build on these principles. This is the foundational action that separates a real business continuity plan from a box-ticking exercise.
The Plan: A 30-Day Move to Restore Control
Forget boiling the ocean. This is a focused, 30-day move to establish control and build a system you can trust. The goal is tangible progress, not perfection.
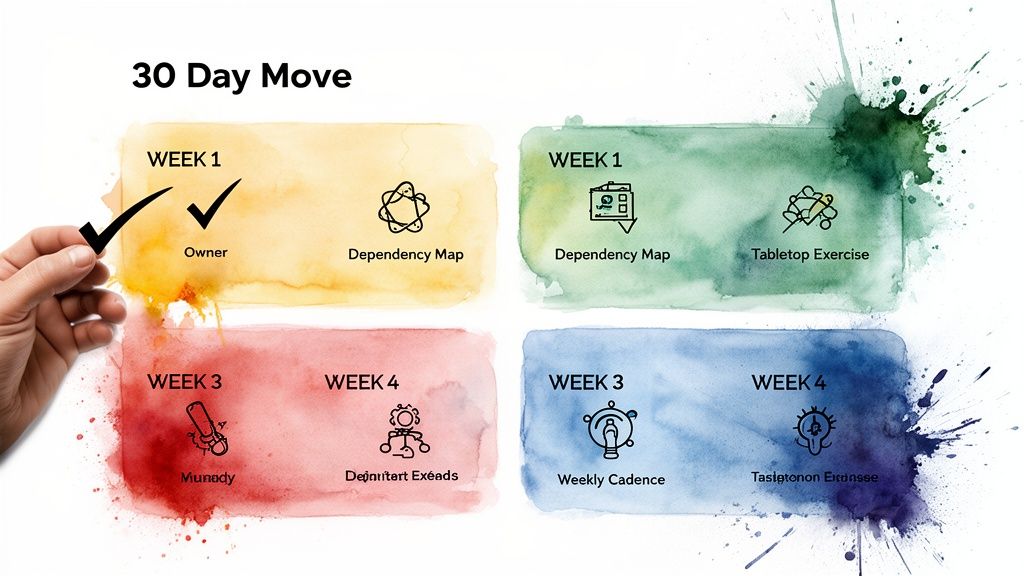
Here is a simple, week-by-week sequence to move from a paper plan to a working system.
Week 1. Name the Owner and Define the Outcome. Appoint a single owner for the continuity program. Their first task: work with leadership to agree on the top 5 most critical business services. The outcome is a single point of accountability and a ruthlessly prioritized list of what truly matters.
Week 2. Map the Handoffs and Define Done. The owner selects one critical service and maps its dependencies: the key people, systems, and vendors required for it to function. The definition of done is a "blast radius" map that makes single points of failure visible. This simple mapping exercise often reveals shocking risks, like discovering your primary payment processor and its "backup" both rely on the same obscure cloud provider.
Week 3. Remove One Blocker and Ship One Fix. Run a 30-minute tabletop exercise for that one service with its key players. Simulate a plausible failure: "Our main payment vendor is offline. Go." The owner facilitates by asking direct questions: "Who makes the first call? Who has the authority to approve a fix?" This pressure test will reveal the biggest gaps. The outcome is a prioritized list of the top 3 urgent fixes. For a framework, our crisis management plan template is a great starting point.
Week 4. Start the Weekly Cadence and Publish Proof. The owner starts a recurring 30-minute weekly check-in to track progress on the action items from the tabletop exercise. By the end of the week, they publish a one-page proof snapshot showing the continuity status for that service, owners for each fix, and a clear "red, yellow, green" status. This makes progress visible.
This repeatable process builds resilience one sprint at a time, reducing both coordination tax and risk exposure.
Proof: What Your Board Will Accept
A plan on paper is hope. A business continuity plan that actually works produces evidence. When auditors, insurers, or your board asks, “Are we ready?” you need to show them proof. This is how you graduate from compliance theater to genuine operational resilience.

You must track signals that progress is real. Your leadership cares about outcomes, not activities.
| Vague Activity (Hope) | Inspectable Proof (Control) |
|---|---|
| "We have a business continuity plan." | A current inventory of critical systems, mapped to specific business services. |
| "We did a tabletop exercise." | Dated tabletop exercise logs with attendance, a summary of the scenario, and a list of tracked action items with owners. |
| "Our data is backed up." | Dated proof of successful backup and restore tests for critical data sets. |
A plan without tested RTOs and RPOs is not a plan; it’s a guess. Your board wants proof that you have made deliberate, risk-informed decisions. Focus on collecting these three types of evidence:
- Proof of Ownership and Scope: A simple document listing the program owner and the approved short-list of your top 5-10 critical business services. This shows you know what matters.
- Proof of Testing: The one-page summaries from your tabletop exercises. They show what was tested, who was there, what broke, and what you're doing to fix it. This proves your program is alive and improving.
- Proof of Recovery Capability: Dated logs from successful data restore tests. Proof of a strategy for backing up your database is a start, but proof of restoration is what counts.
These artifacts transform your continuity program from a theoretical exercise into a defensible system of operational control. This is the evidence that lets you look leadership in the eye and say, "Yes, our plan works, and here is the proof."
Your Next Step: From Plan to Action
You've seen how a dusty binder fails and how a living system built on ownership and cadence succeeds. You now have a 30-day plan to build a business continuity plan that actually works for your most critical service. The process is designed to restore control, protect trust, and let your team ship what matters instead of fighting fires.
The alternative is to wait for the next crisis to reveal the gaps for you. A proactive, operational approach ensures fewer surprises and no public embarrassment. You can build a calmer, faster, and more resilient organization.
CTO Input provides fractional and interim CTO, CIO, and CISO leadership to help you install this kind of operating system. We restore clear ownership, clean decisions, and reliable execution across your technology and security.
Ready to move from a paper plan to a system you can inspect? Book a clarity call to map your decision rights and build a 30-day move.